

Back to top
miCORE Amplicon Metagenomics

miCORE Amplicon Metagenomics is Microsynth’s standard Illumina-based sequencing service for profiling microbial communities. Using one of four validated marker regions, it enables the characterization of bacterial (V4 or V34), archaeal (V34 Archaea), and fungal (ITS) communities.
For added convenience, DNA extraction can be included for soil and fecal samples. Sequencing data are processed through our standardized bioinformatics pipeline, providing comprehensive taxonomic profiling and ready-to-use results.
Configure your project in the Microsynth webshop, receive instant pricing, and place your order online – no quotation required.
Modular Workflow
Outsource the complete workflow or select specific modules. Our process is designed for flexibility. Typical steps include:

Raw data includes:
- Sequencing quantity and quality assessment (.xlsx)
- Raw sequencing data (two .fastq files per sample)
- Summary report (.pdf)
Primer Systems
Choose the primer system that best fits your research focus.
| Target Organism / Application | Primer System | Amplicon Size (bp) | Key Benefit |
| Bacteria | 16S (V4) | ~300 | Recommended as a broad-range marker when both Bacteria and Archaea should be detected. |
| Bacteria | 16S (V34) | ~460 | Typically used when the target is restricted to Bacteria only. |
| Fungi | ITS2 | 300-400 | Amplifies the fungal ITS2 region and is recommended when fungal identification is the primary focus. |
| Archaea | V34 | 390 | Optimized for the amplification of archaeal taxa, particularly from environmental samples |
Bioinformatics Analysis
Our standardized bioinformatics workflow transforms raw Illumina amplicon sequencing data into biologically meaningful insights, providing an intuitive overview of microbial community composition, diversity, and taxonomic structure.
The analysis results are delivered as a comprehensive set of publication-ready figures, interactive visualizations, and data files, including:
- Interactive analysis report (.html)
- Amplicon Sequence Variants (ASVs / zOTUs) (.fasta)
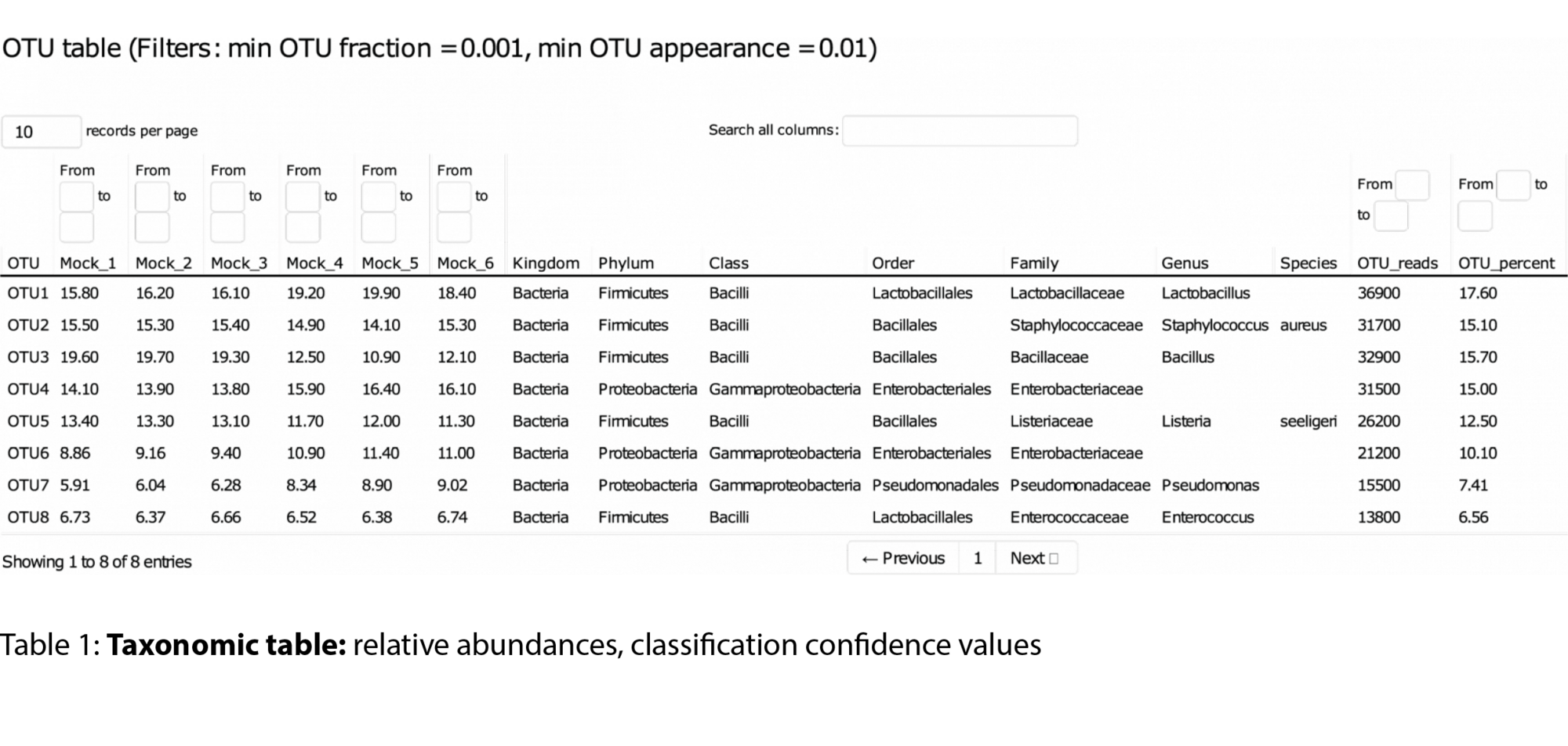
- ASV abundance, taxonomy assignments, and confidence scores (.tsv, .xlsx)
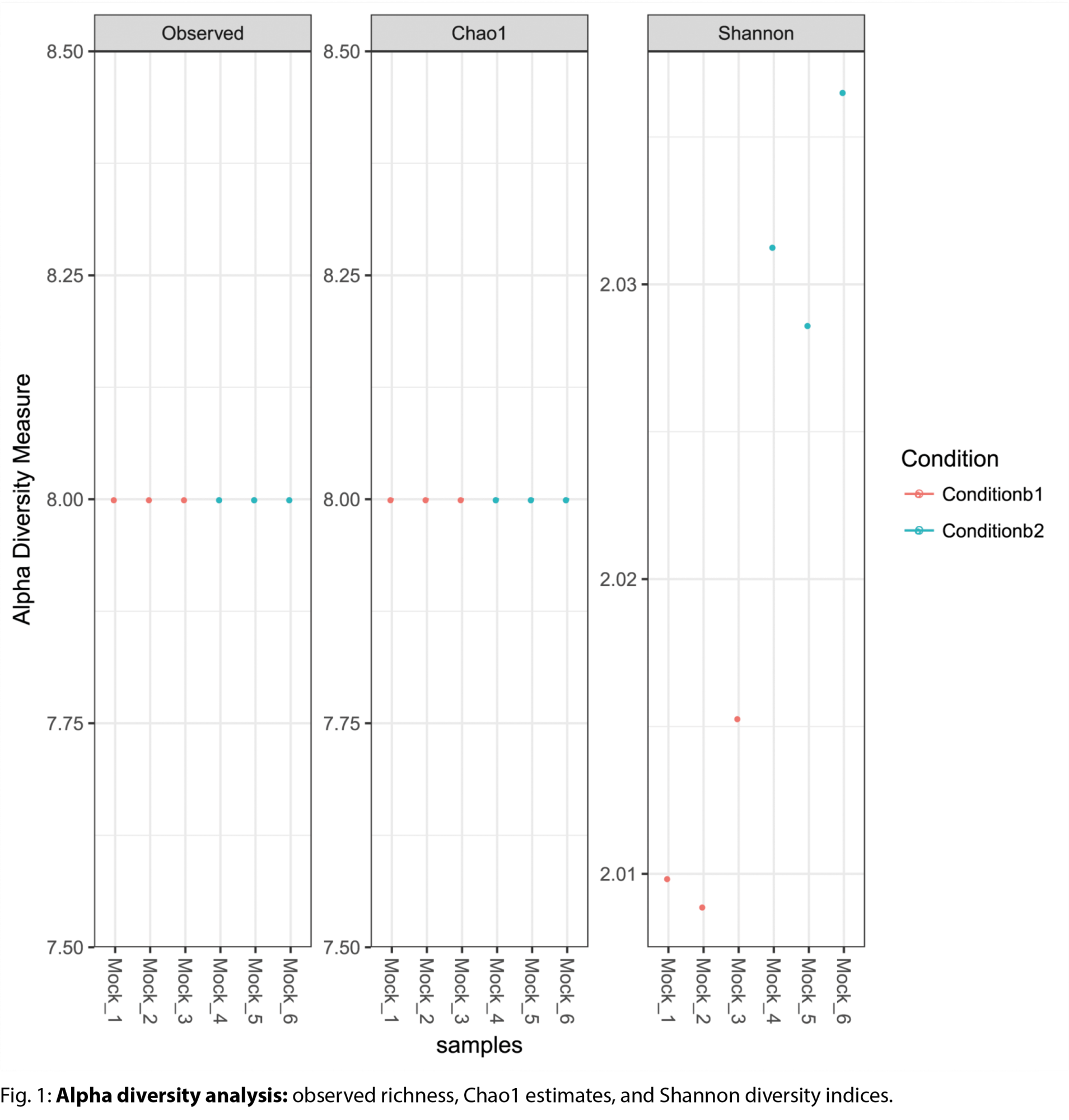
- Alpha diversity analyses and rarefaction curves (.tsv, .pdf)
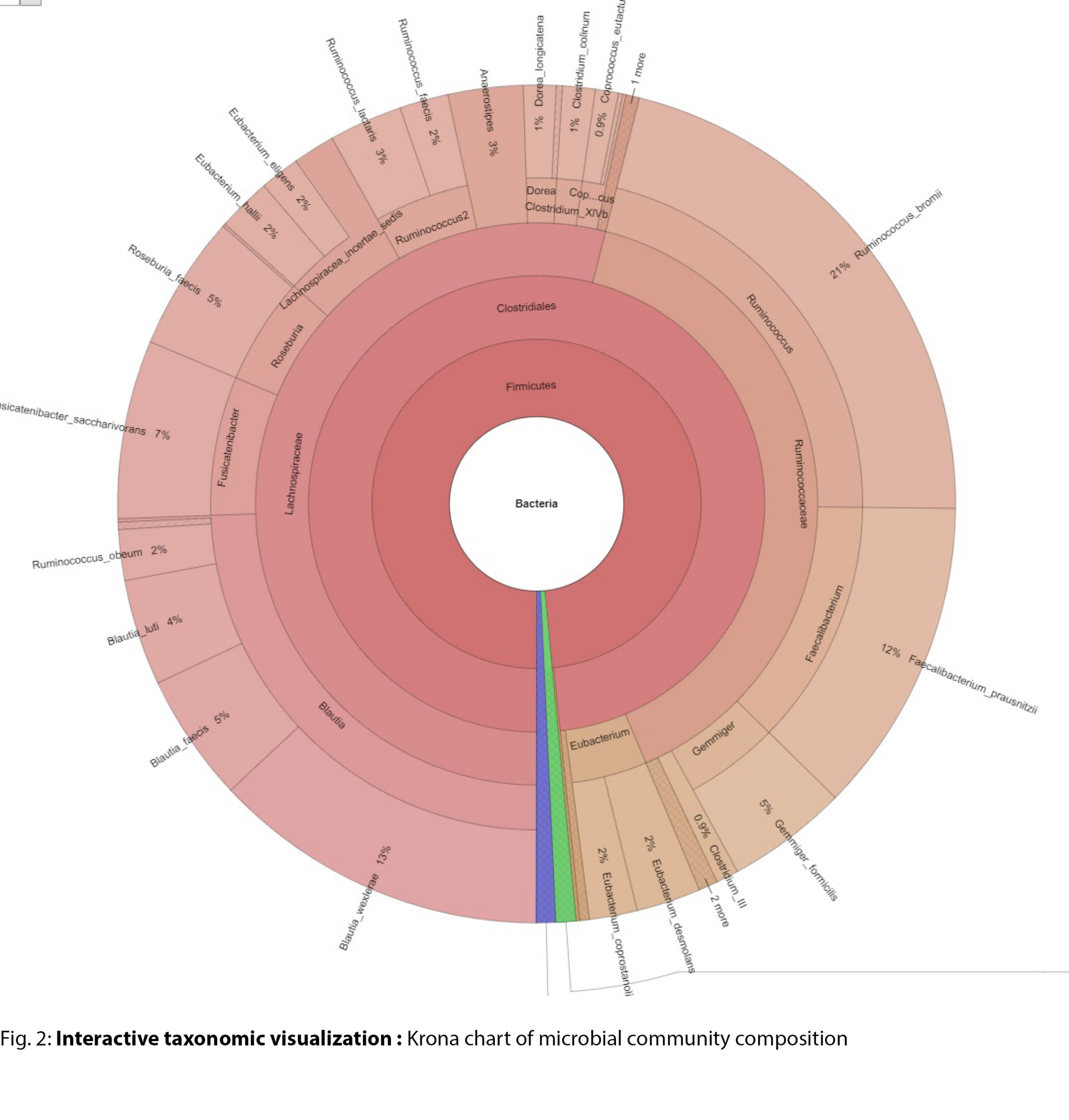
- Interactive Krona plots for taxonomic exploration (.html)
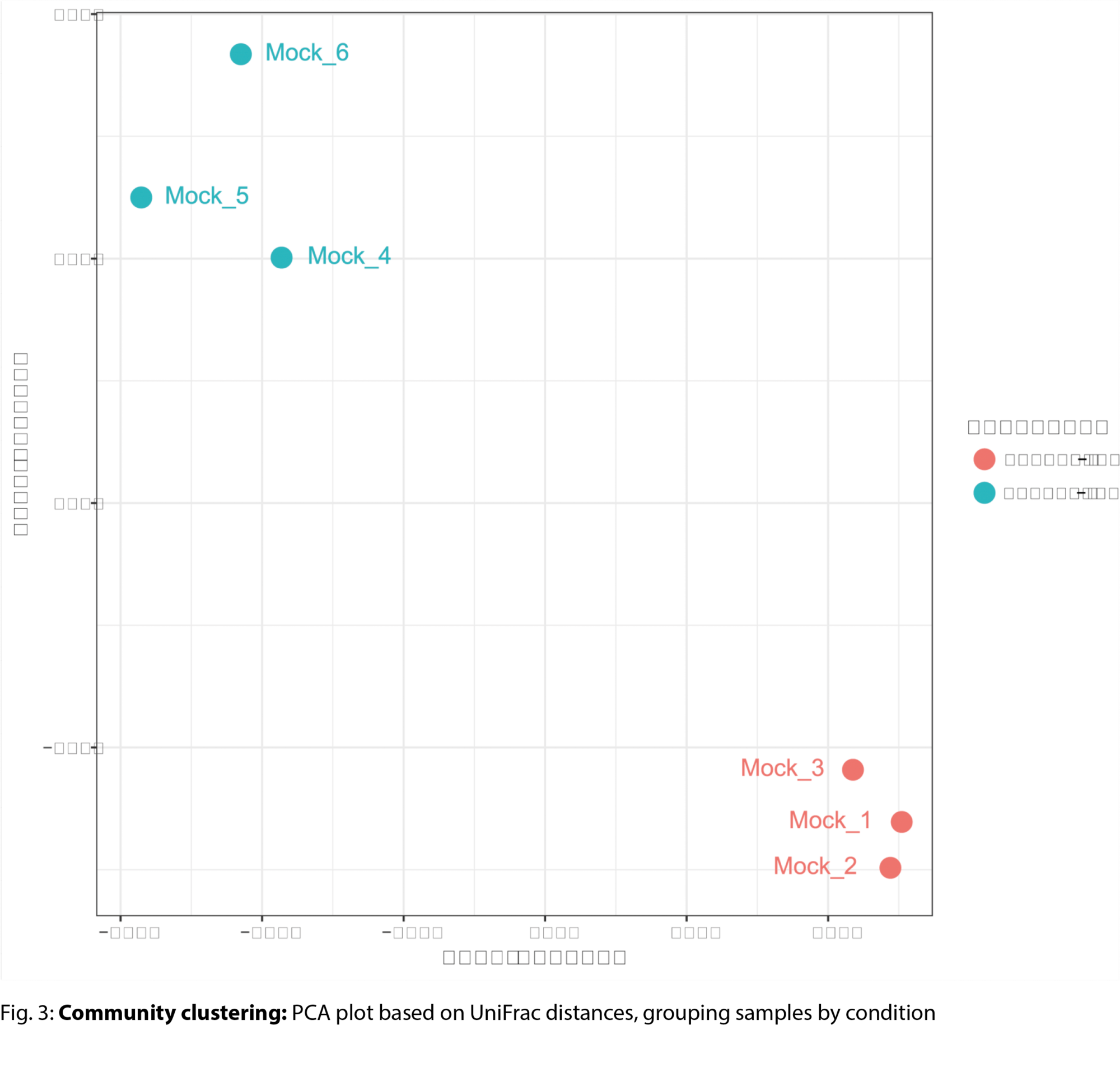
Example Results
All results are delivered in publication-ready figures and interactive formats, providing both high-level overviews and nucleotide-level detail.
Turnaround Time
- Library preparation and sequencing only: 15 working days
- Bioinformatics analysis: +3 working days
- DNA isolation: +5 working days
- Express processing is available on request, subject to feasibility
Sample Requirements
- See User Guide
Custom Services (Available on Request)
If our standard miCORE service does not fully meet your project requirements, Microsynth also offers customized solutions. Depending on your needs, we can support additional sample types for DNA extraction, custom primer systems, and advanced bioinformatics analyses, including functional profiling and comparative statistical analyses.
Please share your project requirements with us, and we will assess their feasibility and provide a customized quotation where appropriate.